jsdelivr 是否提供与其他 CDN 相同的服务?

jsDelivr 相同 CDN:探索替代方案与优化策略
在现代Web开发中,内容分发网络(CDN)扮演着至关重要的角色,它们不仅能够加速全球内容的交付,还能减少服务器负载,提升用户体验,jsDelivr作为广受欢迎的开源CDN服务,以其快速、免费且可靠的特点赢得了开发者的青睐,考虑到网络环境多样性和潜在的访问限制,了解jsDelivr的替代方案同样重要,本文将深入探讨与jsDelivr相似的CDN服务,并通过表格形式对比分析,同时针对常见问题提供FAQ环节,最后附上小编的个人见解。
一、jsDelivr 简介
jsDelivr是一个免费的公共CDN服务,专门用于托管JavaScript、CSS等前端库文件,旨在通过全球分布式网络加速这些资源的加载速度,它支持众多流行的前端框架和库,如React、Vue、jQuery等,以及字体图标库如Font Awesome,用户只需在HTML文件中引用jsDelivr提供的链接,即可轻松实现资源的快速加载和版本控制。
二、jsDelivr 的主要功能
全球加速:利用全球多个节点,确保用户无论身在何处都能快速访问所需资源。
自动更新:随着前端库的新版本发布,jsDelivr会自动更新其托管的文件,确保用户始终使用最新版本。

版本管理:支持通过URL参数指定特定版本,便于开发者进行兼容性测试和回滚操作。
压缩与优化:提供压缩后的文件版本,减少传输体积,加快加载速度。
广泛覆盖:涵盖几乎所有主流的前端库和框架,满足不同项目的需求。
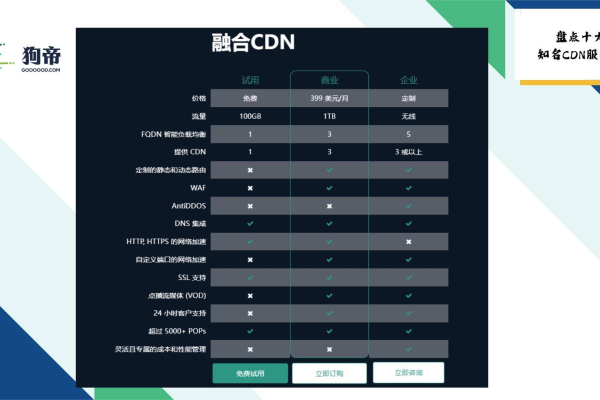
三、与jsDelivr 相同cdn有哪些?
| 特性 | jsDelivr | unpkg.com | fastly.js | cdnjs.com | jsdelivr.b-cdn.net |
| 支持的库数量 | 海量 | 丰富 | 较少 | 中等 | 一般 |
| 全球节点数量 | 众多 | 多 | 少 | 较多 | 一般 |
| 是否支持HTTP/2 | 是 | 是 | 否 | 是 | 是 |
| 是否支持自动压缩 | 是 | 是 | 否 | 是 | 是 |
| 是否支持版本管理 | 是 | 是 | 否 | 是 | 是 |
| 官网或文档 | [jsDelivr官网](https://www.jsdelivr.com/) | [unpkg.com](https://unpkg.com/) | [fastly.js](https://www.fastly.js/) | [cdnjs.com](https://cdnjs.com/) | [jsdelivr.b-cdn.net](http://jsdever.b-cdn.net/) |
| 国内镜像 | 无官方 | 有 | 无 | 有 | 无 |
信息是基于一般情况下的了解,并且可能会随着时间的推移而发生变化,建议在使用前访问各个CDN的官方网站以获取最新和最准确的信息。

四、常见问题解答(FAQ)
Q1:为什么需要使用CDN?
A: CDN可以显著加速全球范围内的内容加载速度,减轻源站服务器压力,提升网站性能和用户体验。
Q2:如何选择适合自己的CDN服务?
A: 考虑因素包括支持的库数量、全球节点分布、是否支持HTTP/2和自动压缩、易用性以及是否有国内镜像等。

Q3:如果jsDelivr在某些地区访问不稳定,怎么办?
A: 可以考虑使用其他CDN服务作为备份,或者在国内选择有镜像的服务以提高访问速度和稳定性。
小编认为,虽然jsDelivr以其强大的功能和广泛的库支持成为了许多开发者的首选CDN服务,但考虑到网络环境的多样性和潜在访问限制,了解并准备一些替代方案是明智之举,在选择CDN服务时,除了基本的加速和压缩功能外,还应关注其全球节点分布、HTTP/2支持、版本管理以及是否有国内镜像等因素,通过合理选择和搭配使用CDN服务,可以进一步提升Web项目的性能和用户体验。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22