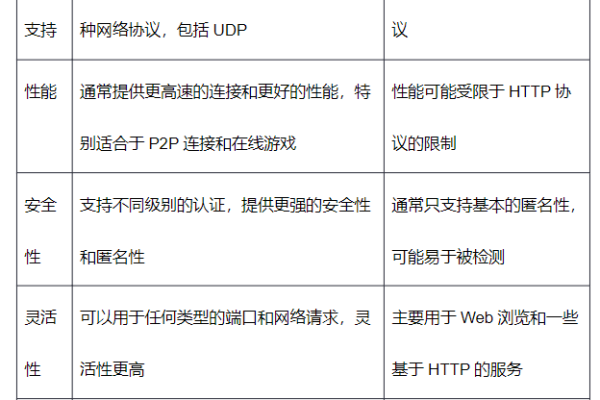
如何在Linux系统中配置全局Socks代理?

all_proxy 或编辑配置文件来实现。
在Linux系统中,全局使用SOCKS代理可以通过多种方式实现,包括配置系统级代理、使用代理软件以及设置环境变量等,以下是对如何在Linux上全局使用SOCKS代理的详细探讨:
一、配置系统级代理
1. 修改/etc/environment文件
通过编辑/etc/environment文件,可以为整个系统设置环境变量,包括HTTP和SOCKS代理,这种方法适用于所有用户,并且对所有应用程序生效。
步骤:
打开终端并以root权限编辑/etc/environment文件:
sudo nano /etc/environment
添加以下行(假设代理服务器IP为192.168.41.217,端口为10811):
export http_proxy=http://192.168.41.217:10811/ export https_proxy=http://192.168.41.217:10811/ export ftp_proxy=http://192.168.41.217:10811/ export no_proxy="localhost,127.0.0.1,::1"
保存并退出编辑器,然后重启系统或重新登录以使更改生效。
2. 修改/etc/profile文件
另一种方法是编辑/etc/profile文件,该方法同样适用于所有用户,并且对所有应用程序生效。
步骤:
打开终端并以root权限编辑/etc/profile文件:
sudo nano /etc/profile
在文件末尾添加以下行:
export http_proxy=http://192.168.41.217:10811/ export https_proxy=http://192.168.41.217:10811/ export ftp_proxy=http://192.168.41.217:10811/ export no_proxy="localhost,127.0.0.1,::1"
保存并退出编辑器,然后执行以下命令以使更改立即生效:
source /etc/profile
二、使用代理软件
tsocks
tsocks是一个轻量级的SOCKS代理客户端,可以将指定的应用程序流量通过SOCKS代理转发。
安装与配置:
安装tsocks:
sudo apt-get install tsocks
编辑配置文件/etc/tsocks.conf修改为:
local = 192.168.1.0/255.255.255.0 #本地网络地址范围 server = 127.0.0.1 # SOCKS服务器IP server_type = 5 # SOCKS服务版本 server_port = 9999 # SOCKS服务使用的端口
使用tsocks命令运行需要代理的应用程序,
tsocks curl http://myexternalip.com/raw
三、设置环境变量
对于单个用户或特定应用程序,可以通过设置环境变量的方式来使用SOCKS代理。
步骤:
编辑用户的shell配置文件(如~/.bashrc或~/.zshrc),添加以下行:
export ALL_PROXY="socks5://192.168.41.217:10811" export all_proxy="socks5://192.168.41.217:10811" export http_proxy="http://192.168.41.217:10811" export https_proxy="http://192.168.41.217:10811" export ftp_proxy="http://192.168.41.217:10811" export no_proxy="localhost,127.0.0.1,::1"
保存并退出编辑器,然后执行以下命令以使更改立即生效:
source ~/.bashrc # 如果使用的是bash shell # source ~/.zshrc # 如果使用的是zsh shell
四、常见问题与解决方案
Q1: 如何验证SOCKS代理是否配置成功?
A1: 可以通过访问外部网站来验证代理是否配置成功,使用curl命令访问一个外部网站:
curl -I http://www.google.com
如果返回了HTTP状态码200,则说明代理配置成功。
Q2: 如果某些应用程序无法通过SOCKS代理访问外部网络怎么办?
A2: 确保这些应用程序也支持通过环境变量或配置文件指定代理,如果不支持,可以尝试使用tsocks等工具将这些应用程序的流量转发到SOCKS代理。
Q3: 如何取消SOCKS代理设置?
A3: 可以通过取消设置环境变量或编辑相关配置文件来实现,对于环境变量,可以使用unset命令取消设置:
unset http_proxy unset https_proxy unset ftp_proxy unset no_proxy unset ALL_PROXY unset all_proxy
对于配置文件,可以删除或注释掉相关的代理设置行。
Linux上全局使用SOCKS代理可以通过多种方式实现,具体方法取决于用户需求和应用场景,在实际应用中,可以根据具体情况选择合适的方法进行配置,需要注意代理服务器的安全性和稳定性,以确保网络访问的顺畅和安全。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/11529.html