count数据库

在数据库操作中,COUNT 函数是一个极为关键的聚合函数,用于统计特定数据集中的行数或记录数,它能够帮助我们快速获取关于数据规模和分布的重要信息,从而为数据分析、业务决策等提供有力支持。
`COUNT` 函数的基本用法
统计表中所有行的记录数:使用COUNT(*) 可以统计指定表中的总行数,要统计名为users 的表中所有用户的数量,可以使用以下 SQL 语句:
SELECT COUNT(*) FROM users;
这条语句会返回一个数字,表示users 表中的总行数,无论这些行包含的是何种数据。
统计符合特定条件的记录数:通过在COUNT 函数中使用WHERE 子句,可以筛选出满足特定条件的记录并统计其数量,要统计年龄大于 30 岁的用户数量,可以使用:
SELECT COUNT(*) FROM users WHERE age > 30;
这里的WHERE age > 30 就是筛选条件,只有年龄大于 30 的记录才会被计入统计结果。
统计某一列非空值的数量:如果只想统计某一列中有实际数据(非空)的行数,可以使用COUNT(column_name),要统计users 表中email 列非空的用户数量,可以使用:
SELECT COUNT(email) FROM users;
这将忽略email 列为空的行,只统计有有效邮件地址的用户数量。
`COUNT` 函数的使用场景
数据验证和完整性检查:在数据录入或数据迁移过程中,经常需要使用COUNT 函数来验证数据的完整性,在将一批新用户数据导入到数据库后,可以通过COUNT(*) 检查导入的数据行数是否与预期一致,以确保数据没有丢失或重复导入。
分析用户行为和业务趋势:通过对特定行为或事件相关的记录进行计数,可以了解用户的活跃度、偏好以及业务的变化趋势,统计某个电商平台上不同时间段内用户的购买次数,可以帮助分析销售高峰和低谷,为库存管理和营销策略提供依据。
数据分布统计:利用COUNT 函数结合分组(GROUP BY)语句,可以统计不同类别或维度下的数据分布情况,按地区统计用户数量,或者按产品类别统计订单数量等,这有助于深入了解数据的结构和特征。
`COUNT` 函数的常见错误及解决方法
忽略空值问题:在使用COUNT(column_name) 时,如果该列存在空值(NULL),这些空值将不会被计入统计结果,有一个包含用户生日信息的表,其中部分用户的生日为空,如果直接使用COUNT(birthday) 统计有生日信息的用户数量,得到的结果会比实际用户总数少,解决方法是在统计时明确处理空值,根据具体需求决定是否将其纳入统计范围。
重复统计问题:在多表关联查询中,可能会出现重复统计的情况,有两个表orders 和users,通过用户 ID 关联起来,如果直接对关联结果使用COUNT(*),可能会因为一个用户有多个订单而导致该用户被重复计算多次,为了避免这种情况,可以使用DISTINCT 关键字来确保每个用户只被计算一次,如:
SELECT COUNT(DISTINCT user_id) FROM orders INNER JOIN users ON orders.user_id = users.id;
性能问题:当对大规模数据表执行COUNT 操作时,尤其是在复杂的查询条件下,可能会导致查询性能下降,为了提高性能,可以考虑以下方法:一是优化数据库的索引结构,确保查询条件所涉及的列都有适当的索引;二是避免在COUNT 查询中进行不必要的计算或函数调用;三是对于频繁执行的COUNT 查询,可以考虑使用缓存技术来存储结果,减少重复查询的开销。
相关示例
假设有一个名为students 的学生信息表,包含以下列:id(学生编号)、name(姓名)、age(年龄)、grade(成绩),以下是一些常见的COUNT 操作示例:
统计学生总数:
SELECT COUNT(*) FROM students;
统计年龄大于 20 岁的学生数量:
SELECT COUNT(*) FROM students WHERE age > 20;
统计成绩不为空的学生数量:
SELECT COUNT(grade) FROM students;
按成绩等级统计学生数量(假设成绩等级分为 A、B、C 等):
SELECT grade, COUNT(*) FROM students GROUP BY grade;
FAQs
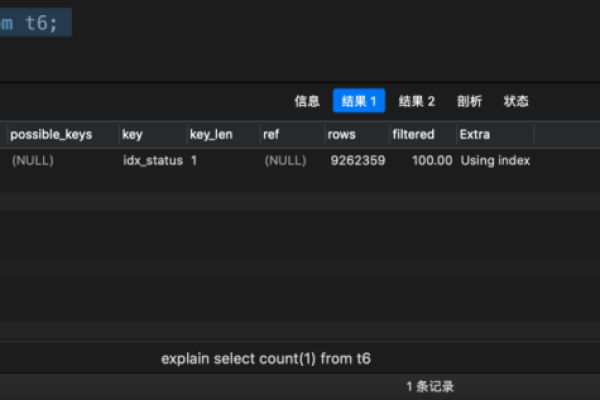
**Q:COUNT(*) 和COUNT(1) 有什么区别?
A: 在实际使用中,COUNT(*) 和COUNT(1) 通常具有相同的效果,都是统计表中所有行的数量,从语义上讲,COUNT(*) 更直观地表示统计所有行,而COUNT(1) 则是对常量 1 进行计数,在一些数据库优化方面,可能会有细微的差异,但大多数情况下可以互换使用。
Q: 为什么有时候COUNT 的结果不太准确?
A: 这可能是由于多种原因导致的,要确保查询语句的正确性,包括表名、列名、条件等是否正确书写,要考虑数据的一致性和完整性,例如是否存在数据并发修改导致的统计偏差,如果涉及到多表关联查询,要注意关联条件是否正确以及是否存在重复统计或遗漏统计的情况,数据库本身的性能和配置也可能影响COUNT 操作的准确性和效率,需要根据实际情况进行调整和优化。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/112313.html