如何顺利完成域名备案流程?

域名备案流程详解
购买云服务器及域名
在开始域名备案之前,首先需要购买云服务器和域名,用户可以选择阿里云、腾讯云等平台,根据自己的需求选择合适的配置进行购买,以阿里云为例:
1、注册阿里云账号:访问[阿里云官网](https://www.aliyun.com/),注册一个账号并完成登录。
2、购买云服务器:进入阿里云控制台后,选择“云服务器ECS”服务,根据需求选择适合的服务器配置进行购买。
3、购买域名:在阿里云的“域名注册”页面(https://wanwang.aliyun.com),输入想要注册的域名,检查是否已被注册,选择合适的后缀进行购买。.com、.cn、.net等。
4、实名认证:购买域名后,需要进行实名认证,登录阿里云控制台,找到已购买的域名,按照提示提交实名认证资料,包括身份证明文件等。
5、域名解析:在域名管理页面,将域名解析到已购买的云服务器IP地址,以便后续网站能够正常访问。
ICP备案
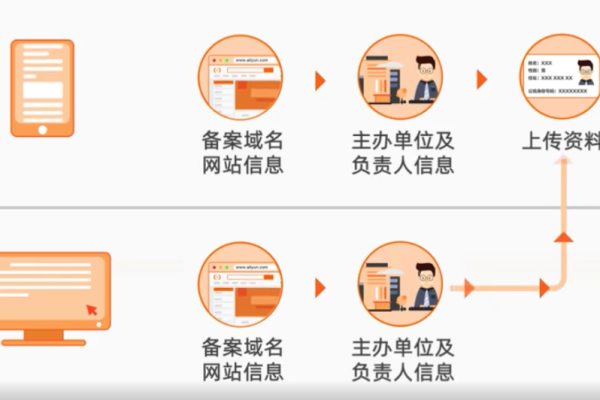
完成域名注册和实名认证后,接下来需要进行ICP备案,ICP备案是指在中国境内提供非经营性互联网信息服务时,必须进行的备案手续,以下是ICP备案的详细步骤:
1、登录备案系统:通过阿里云控制台,进入备案系统(https://beian.aliyun.com)。
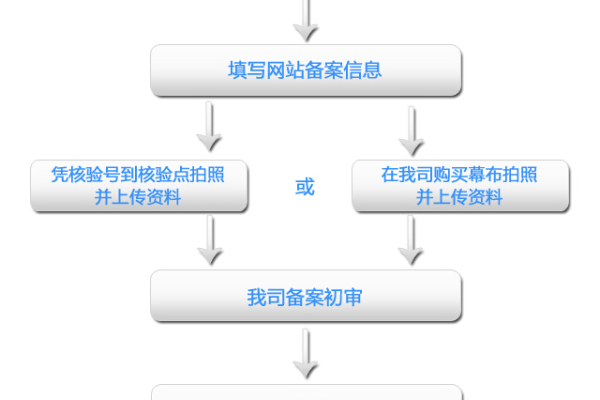
2、填写备案信息:

主体信息:包括主办单位名称、性质、证件类型及号码等。
网站信息:包括网站名称、网站域名、网站用途等,需要注意的是,网站名称不能包含国家、地区、商业词或论坛等敏感词汇。
3、上传资料:根据系统提示,上传相关证件照片,如身份证正反面、营业执照等。
4、真实性核验:部分情况下需要进行人脸识别或视频核验,确保提交的信息真实有效。
5、提交审核:确认所有信息无误后,提交备案申请,阿里云会进行初审,初审通过后会提交给工信部进行最终审核。
6、审核结果:工信部审核通常需要20个工作日左右,如果审核通过,会收到短信和邮件通知,并获得备案号,如果审核未通过,需根据反馈意见进行修改后重新提交。
7、备案号放置:备案成功后,需要在网站的主页面底部放置备案号,并链接至工信部备案管理系统(https://beian.miit.gov.cn)。

公安联网备案
在ICP备案通过后,还需要进行公安联网备案,具体要求如下:
1、访问全国互联网安全管理服务平台:网址为http://www.beian.gov.cn/。
2、注册账号:首次使用时需要注册账号,并进行手机验证和邮箱验证。
3、提交备案申请:登录后,选择“联网备案”管理模块,按照系统提示填写开办主体信息和网站基本信息。
4、等待审核:提交申请后,公安机关会在规定时间内进行审核,审核通过后,会生成公安备案号。
常见问题解答
1、Q1: 域名一定要备案吗?
A1: 不一定,如果使用国内主机或服务器建站,则必须进行备案;如果使用香港主机或海外主机,可以免备案,但需要注意的是,不备案可能会影响网站的访问速度和信任度。

2、Q2: 备案过程中需要注意哪些事项?
A2: 在备案过程中,需要注意以下几点:
确保提交的所有信息真实有效,尤其是身份证件和域名证书。
网站名称不要包含敏感词汇,如国家、地区、商业词等。
保持联系方式畅通,以便接收审核通知。
通过上述步骤,用户可以顺利完成域名的购买与备案流程,确保网站能够合法合规地上线运行。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

配件网站模板_网站模板设置
2024-06-23 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22