如何高效地查询MySQL数据库的数据和错误日志?

mysql.err文件或通过以下命令查找:,,“
bash,sudo tail f /var/log/mysql/error.log,“
MySQL如何查询数据库数据
MySQL是一种广泛使用的关系型数据库管理系统,它支持多种数据查询操作,以下是一些常用的查询方法和示例:
1、基本查询:使用SELECT语句来检索数据。
查询所有列的所有行:SELECT * FROM table_name;
查询特定列的所有行:SELECT column1, column2 FROM table_name;
2、条件查询:使用WHERE子句来过滤数据。
查询满足条件的行:SELECT * FROM table_name WHERE condition;
3、排序查询:使用ORDER BY子句来对结果进行排序。
按某列升序排序:SELECT * FROM table_name ORDER BY column_name ASC;
按某列降序排序:SELECT * FROM table_name ORDER BY column_name DESC;
4、分组查询:使用GROUP BY子句来对结果进行分组。
按某列分组并计算聚合函数:SELECT column1, aggregate_function(column2) FROM table_name GROUP BY column1;
5、限制查询结果:使用LIMIT子句来限制返回的行数。

限制返回的行数:SELECT * FROM table_name LIMIT number;
6、联合查询:使用UNION运算符来合并多个查询的结果。
合并两个查询的结果:SELECT column1, column2 FROM table1 UNION SELECT column1, column2 FROM table2;
7、连接查询:使用JOIN子句来连接多个表并查询数据。
连接两个表并查询数据:SELECT table1.column1, table2.column2 FROM table1 JOIN table2 ON table1.common_field = table2.common_field;
8、子查询:在一个查询中嵌套另一个查询。
子查询作为条件:SELECT * FROM table_name WHERE column_name IN (SELECT column_name FROM another_table);
9、正则表达式查询:使用REGEXP或RLIKE运算符来匹配正则表达式。
匹配正则表达式:SELECT * FROM table_name WHERE column_name REGEXP 'pattern';
10、索引优化:使用索引来提高查询性能。
创建索引:CREATE INDEX index_name ON table_name (column_name);
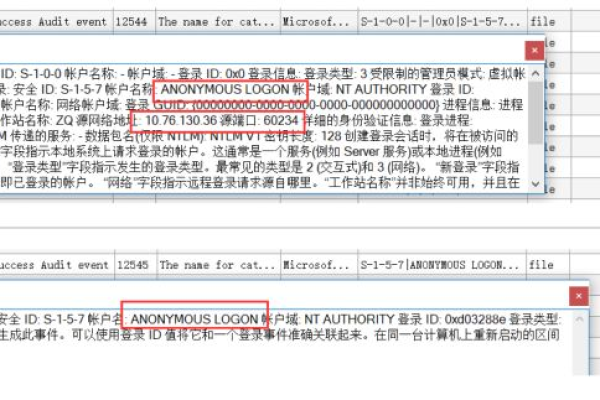
查询数据库错误日志(MySQL)
在MySQL中,可以通过以下方法查看错误日志:
1、查找错误日志文件:MySQL的错误日志文件位于MySQL的数据目录下,文件名为hostname.err,其中hostname是MySQL服务器的主机名。
2、使用命令行查看错误日志:可以使用tail、cat等命令来查看错误日志文件的内容。
查看错误日志的最后几行:tail n number /path/to/hostname.err
查看错误日志的全部内容:cat /path/to/hostname.err
3、配置错误日志:可以在MySQL配置文件中设置错误日志的相关参数,例如日志文件的位置和大小限制,配置文件通常位于/etc/my.cnf或/etc/mysql/my.cnf。
4、使用MySQL管理工具查看错误日志:可以使用phpMyAdmin、MySQL Workbench等图形化管理工具来查看和管理MySQL的错误日志。
FAQs(常见问题解答)
问题1:如何定期清理MySQL的错误日志?
答:可以编写脚本或使用cron作业来定期清理MySQL的错误日志,可以使用>运算符来清空日志文件的内容:> /path/to/hostname.err。
问题2:如何配置MySQL的错误日志格式?
答:可以在MySQL配置文件中设置log_error参数来指定错误日志的格式和位置。
[mysqld] log_error = /path/to/customhostname.err
保存配置文件后,需要重启MySQL服务使更改生效。
| 步骤 | SQL 语句 | 描述 | |
| 1. 连接到MySQL服务器 | mysql u username p |
使用用户名和密码登录MySQL服务器。 | |
| 2. 选择数据库 | USE database_name; |
选择包含错误日志的数据库。 | |
| 3. 查询错误日志表 | SELECT * FROM |
mysql_error_log; |
默认情况下,MySQL错误日志存储在名为mysql_error_log的表中,如果使用不同的配置,请相应地更改表名。 |
| 4. 查询特定错误日志条目 | SELECT * FROM |
mysql_error_logWHERE error LIKE '%error_message%'; |
使用LIKE操作符和通配符%来搜索包含特定错误信息的日志条目。 |
| 5. 查询特定时间段的错误日志 | SELECT * FROM |
mysql_error_logWHERE timestamp BETWEEN 'start_time' AND 'end_time'; |
使用BETWEEN操作符来查询特定时间段内的错误日志,将start_time和end_time替换为具体的日期和时间。 |
| 6. 查询特定错误级别的日志 | SELECT * FROM |
mysql_error_logWHERE level = 'error_level'; |
使用level字段来查询特定错误级别的日志,例如error、warning或note。 |
具体的表名和字段名称可能因MySQL配置而异,如果需要更详细的信息,请参考MySQL官方文档。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11