如何通过MapReduce技术高效实现文章相似度计算?探究其核心原理与应用策略?

MapReduce 在文章相似度计算中的应用
文章相似度计算是信息检索、文本挖掘和自然语言处理等领域的重要任务,MapReduce 是一种并行计算框架,适用于大规模数据处理,本文将详细阐述如何利用 MapReduce 来计算文章之间的相似度。
MapReduce 框架概述
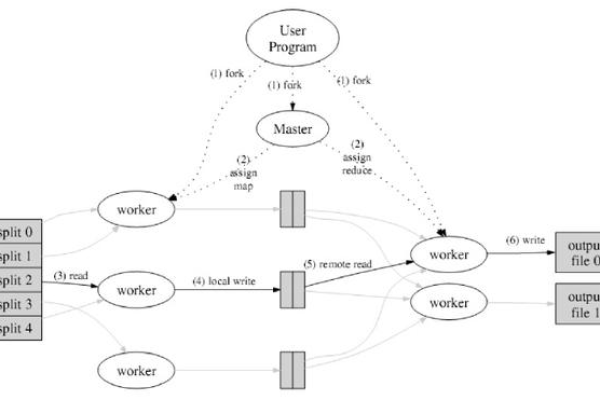
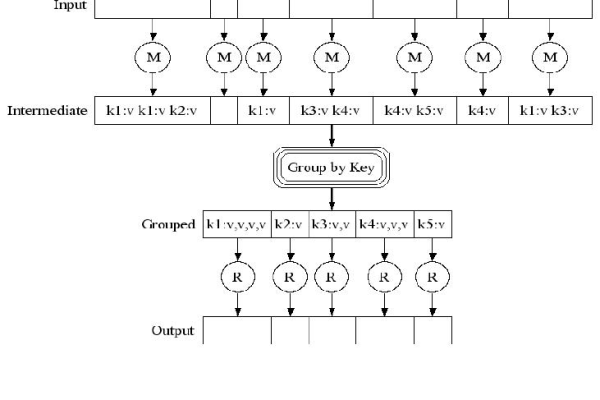
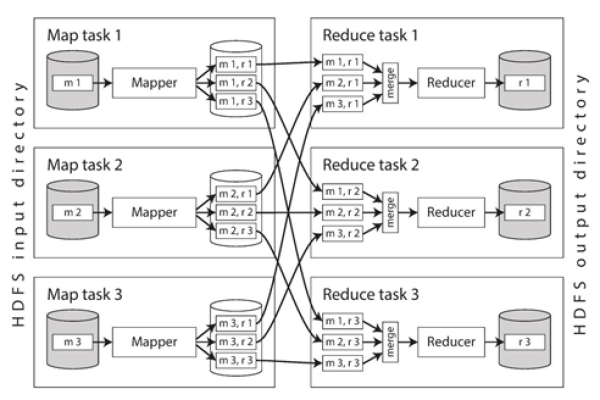
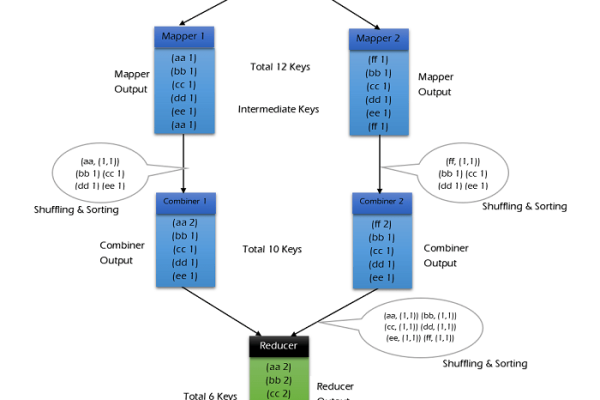
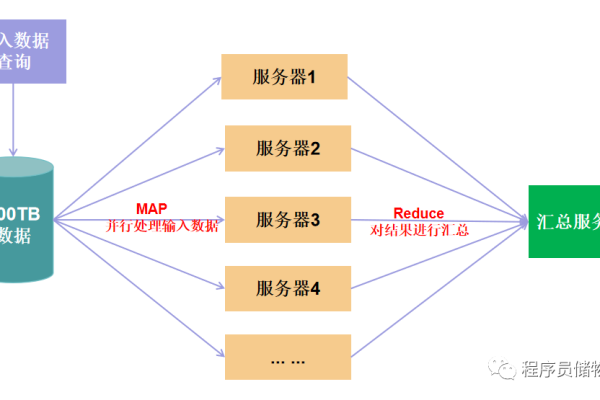
MapReduce 框架由两个主要操作组成:Map 和 Reduce,Map 阶段将输入数据转换成键值对,Reduce 阶段对相同键的值进行聚合。
Map 阶段
1、输入数据:文本文件或文章集合。
2、Map 函数:将每篇文章分解成单词或短语,并生成键值对。
键:单词或短语。
值:文章ID。
Reduce 阶段
1、中间数据:Map 阶段生成的所有键值对。
2、Reduce 函数:对相同键的值进行聚合,通常用于统计每个单词在所有文章中的出现次数。
文章相似度计算步骤
步骤一:词频统计
1、Map 阶段:对每篇文章进行分词,生成键值对(单词,文章ID)。
2、Reduce 阶段:对每个单词的值进行聚合,得到每个单词在所有文章中的出现次数。
步骤二:计算余弦相似度
1、Map 阶段:对于每对文章,计算它们的词频向量。
2、Reduce 阶段:计算每对文章的余弦相似度。
具体实现
Map 阶段 词频统计
def map_function(article_id, article_text):
words = article_text.split()
for word in words:
yield (word, (article_id, 1))
Reduce 阶段 词频统计
def reduce_function(word, values):
word_count = sum([count for _, count in values])
return (word, word_count)
Map 阶段 余弦相似度
def map_function(article_id, article_text):
words = article_text.split()
word_freq = {}
for word in words:
word_freq[word] = word_freq.get(word, 0) + 1
return (article_id, word_freq)
Reduce 阶段 余弦相似度
def reduce_function(article_id, values):
vector_a = {}
vector_b = {}
for _, freqs in values:
for word, count in freqs.items():
vector_a[word] = vector_a.get(word, 0) + count
vector_b[word] = vector_b.get(word, 0) + count
dot_product = sum(a * b for a, b in zip(vector_a.values(), vector_b.values()))
norm_a = sum(a 2 for a in vector_a.values()) 0.5
norm_b = sum(b 2 for b in vector_b.values()) 0.5
similarity = dot_product / (norm_a * norm_b)
return (article_id, similarity)
MapReduce 框架可以有效地处理大规模数据集,从而实现文章相似度的计算,通过将计算过程分解为 Map 和 Reduce 阶段,可以并行处理数据,提高计算效率,在实际应用中,可以根据具体需求调整 Map 和 Reduce 函数,以适应不同的相似度计算方法。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20