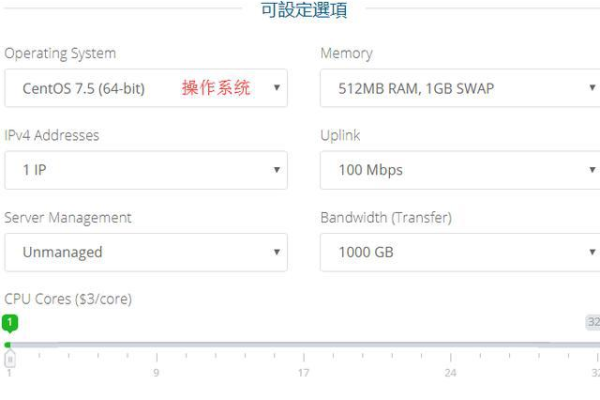
如何快速查看我的VPS配置? (查看vps配置)

快速查看VPS配置,通常可通过SSH登录后执行命令如
uname -a或cat /proc/cpuinfo获取CPU信息,free -m查看内存,df -h检查硬盘空间。
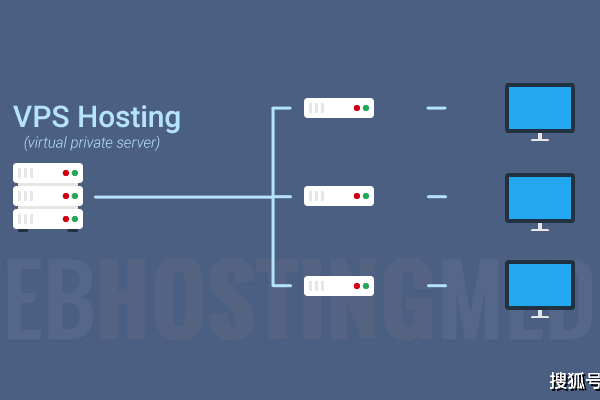
快速查看VPS配置对于系统管理员和网站维护者来说是一个重要的技能,了解服务器的硬件和软件信息有助于进行故障诊断、性能优化和资源管理,以下是一些常用的方法来查看您的VPS(Virtual Private Server,虚拟专用服务器)配置。
使用命令行工具
1. lsb_release 发行版信息
Linux系统中,lsb_release 命令可以显示关于您VPS的发行版信息,这包括了发行版的代号、描述和ID。
lsb_release -a
2. uname 内核与系统信息
uname 命令用于显示系统信息,通过不同的参数,-a、-m 或 -r,可以获得详细的内核版本、硬件名称和内核发布号。
uname -a
3. free 内存信息
free 命令可以显示当前系统的内存使用情况,包括物理内存、交换内存(swap)和缓冲区。
free -h
4. df 磁盘空间
df 命令用于报告文件系统的磁盘空间使用情况,使用 -h 参数可以使大小更易读。
")
df -h
5. top 或 htop 进程监控
top 是一个实时显示系统中各个进程的资源占用状况的命令。htop 是 top 的一个增强版本,提供了彩色界面和更方便的用户操作。
top 或者 htop
6. lshw 硬件配置
lshw(list hardware)命令可以详细列出硬件配置信息,由于需要root权限,所以使用时可能需要用 sudo。
sudo lshw
图形界面工具
如果您的VPS安装了图形用户界面(GUI),也可以使用系统监视器或第三方应用程序如 HWMonitor 等来查看硬件信息。
脚本工具
")
有一些预编译的脚本可以帮助您快速获取服务器的配置信息,
sysinfo 脚本
dmidecode 命令(适用于某些基于硬件的VPS)
查看特定服务配置
对于特定的服务如Apache、Nginx或MySQL等,通常可以在服务的配置文件中查看其配置详情,这些文件通常位于 /etc/ 目录下。
相关问题与解答
Q1: 我可以使用远程桌面连接来查看VPS的配置吗?
")
A1: 可以,但前提是VPS上已经安装并运行了支持远程桌面的服务,如xrdp(针对X Window系统)。
Q2: lshw 命令没有在我的VPS上预装,我该如何安装它?
A2: 您可以使用包管理器(如apt、yum或dnf)来安装 lshw,在基于Debian的系统上,您可以运行 sudo apt-get install lshw。
Q3: 有没有不需要root权限就能查看VPS配置的方法?
A3: 大部分情况下,查看详细的硬件信息需要root权限,查看部分信息如CPU信息、内存使用等可以通过普通用户执行相应命令来实现。
Q4: 我如何通过网络查看远程VPS的配置?
A4: 如果VPS开放了SSH(安全外壳协议),您可以通过SSH客户端连接到VPS,然后使用上述命令查看配置,有些控制面板如cPanel也提供了查看服务器状态的功能。





热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11