快云VPS上手指南 (快云vps如何使用)

快云VPS使用指南提供了详细的步骤和指导,帮助用户了解如何配置和管理其虚拟私人服务器,包括安装操作系统、设置网络和优化性能等。
快云VPS上手指南 (快云vps如何使用)
快云VPS(Virtual Private Server,虚拟专用服务器)是一种基于云计算技术的服务器服务,它为用户提供了独立、灵活、可扩展的服务器环境,本文将为您详细介绍如何上手使用快云VPS,包括购买、登录、配置等方面的内容。
购买快云VPS
1、访问快云官网:在浏览器中输入快云官网网址,进入快云官方网站。
2、注册账号:点击官网右上角的“注册”按钮,按照提示填写相关信息,完成账号注册。
3、登录账号:使用刚刚注册的账号登录快云官网。
4、选择VPS套餐:在官网首页,点击“VPS”菜单,进入VPS产品页面,根据您的需求选择合适的套餐。
5、购买VPS:点击您选择的套餐下方的“立即购买”按钮,进入购买页面,确认订单信息无误后,点击“提交订单”按钮,完成购买。
登录快云VPS
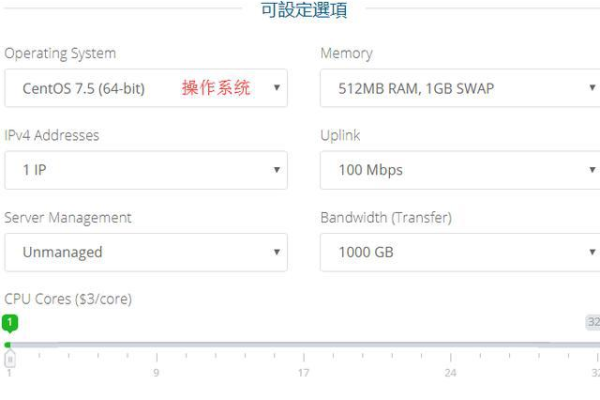
1、获取VPS信息:购买成功后,您可以在快云官网的控制台查看您的VPS信息,包括IP地址、端口号、用户名和密码等。
")
2、使用SSH客户端登录:下载并安装SSH客户端(如PuTTY、Xshell等),输入您的VPS IP地址、端口号、用户名和密码,点击“连接”按钮,成功登录您的快云VPS。
配置快云VPS
1、更新系统:登录成功后,首先建议您更新系统,以获取最新的软件包和安全补丁,在命令行中输入以下命令:
sudo apt-get update sudo apt-get upgrade
2、安装常用软件:根据您的需求,安装相应的软件,如果您需要搭建一个Web服务器,可以安装Nginx或Apache,在命令行中输入以下命令:
sudo apt-get install nginx
3、配置防火墙:为了确保您的VPS安全,建议您配置防火墙,只允许必要的端口对外开放,在命令行中输入以下命令:
sudo ufw allow ssh sudo ufw allow www sudo ufw enable
4、配置网站:如果您已经安装了Web服务器软件,接下来可以配置您的网站,编辑Nginx的配置文件(通常位于/etc/nginx/sites-available/目录下),设置您的网站域名、根目录等信息,然后重启Nginx服务:
sudo service nginx restart
至此,您已经成功上手使用快云VPS,接下来,您可以根据您的需求,继续配置和使用您的VPS。
相关问题与解答
")
1、如何在快云VPS上安装MySQL数据库?
答:在快云VPS上安装MySQL数据库,可以使用以下命令:
sudo apt-get install mysql-server
安装完成后,使用以下命令进行安全配置:
sudo mysql_secure_installation
2、如何在快云VPS上安装PHP环境?
答:在快云VPS上安装PHP环境,可以使用以下命令:
sudo apt-get install php-fpm php-mysql
安装完成后,编辑Nginx的配置文件,添加以下内容:
location ~ .php$ {
include snippets/fastcgi-php.conf;
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
}
然后重启Nginx服务。
")
3、如何在快云VPS上安装Node.js环境?
答:在快云VPS上安装Node.js环境,可以使用以下命令:
curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash - sudo apt-get install -y nodejs
安装完成后,使用以下命令检查Node.js版本:
node -v
4、如何在快云VPS上部署WordPress网站?
答:在快云VPS上部署WordPress网站,首先需要安装Web服务器(如Nginx)、MySQL数据库和PHP环境,从WordPress官网下载最新的WordPress安装包,解压到您的网站根目录,访问您的域名,按照提示完成WordPress的安装过程。







热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11