ssh连接国外服务器

SSH(Secure Shell)是一种加密的网络协议,用于安全地连接和控制远程服务器。通过SSH连接国外服务器,可以实现跨地域的数据传输和管理,提高工作效率和安全性。
如何通过SSH链接国外服务器?
SSH(Secure Shell)是一种网络协议,用于安全地在网络上执行命令和管理服务器,它为远程登录和其他网络服务提供了加密的保护,以防止窃听、连接劫持或其他攻击,以下是通过SSH连接到国外服务器的详细步骤:
获取必要的信息
要连接到一个服务器,你需要以下信息:
1、服务器的IP地址或域名
2、你的用户名
3、服务器上SSH服务的端口号(默认是22,但有时可能不同)
4、可能需要的密码或密钥对

安装SSH客户端
大多数现代操作系统都自带了SSH客户端,但如果你发现没有安装,可以按照你的操作系统进行安装,在Windows上,你可以使用PuTTY或Windows 10中的OpenSSH客户端;在macOS和Linux上,SSH客户端通常已经预装。
连接到服务器
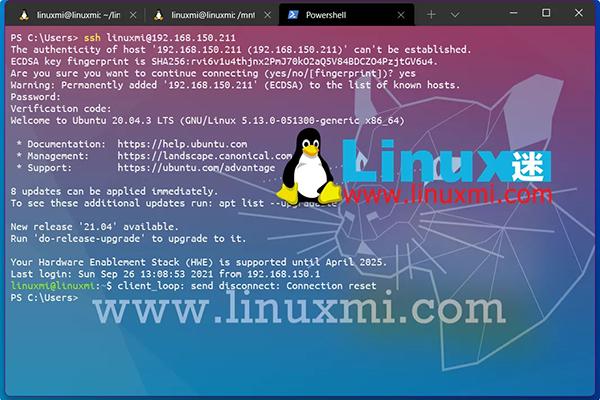
一旦你有了所有必要的信息并且安装了SSH客户端,你可以打开终端(在Windows上可能是命令提示符或PowerShell,或者你可能会使用PuTTY),然后输入以下命令:
ssh 用户名@服务器地址 -p 端口号
接着,系统会提示你输入密码,如果你使用的是密钥对认证,可能需要指定私钥文件,像这样:
ssh -i /path/to/private_key 用户名@服务器地址 -p 端口号
成功连接后,你将会看到远程服务器的命令行界面,并可以开始在远程服务器上执行命令。

使用SSH配置文件
为了方便起见,你可以创建一个SSH配置文件来保存你的服务器信息,这样你就不需要每次连接时都输入这些信息,在Linux和macOS上,这个文件通常是~/.ssh/config,在Windows上则是%userprofile%.sshconfig,配置文件的内容可能看起来是这样的:
Host myserver
HostName example.com
User myusername
Port 22
IdentityFile ~/.ssh/my_private_key 之后,只需输入ssh myserver就能连接到服务器。
相关问题与解答
Q1: 如果SSH连接被拒绝,可能是因为什么原因?
A1: SSH连接被拒绝可能是因为用户名或密码错误,服务器未运行SSH服务,防火墙设置阻止了连接,或者是网络问题。

Q2: 如何找到SSH服务器的IP地址或域名?
A2: 通常,服务器的IP地址或域名会由服务提供商提供,如果你是服务器管理员,可以在服务器上运行ifconfig或ip addr命令查看IP地址。
Q3: 我应该使用密码还是密钥对进行SSH认证?
A3: 使用密钥对更安全,因为它提供了更强的加密,并且可以在不输入密码的情况下进行身份验证,如果你需要更高的安全性,建议使用密钥对。
Q4: 我可以在SSH连接中使用代理吗?
A4: 是的,可以通过设置SSH代理命令(-W选项)或使用SOCKS代理来通过SSH隧道连接到其他服务器,这在进行一些高级网络配置时非常有用。


热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -
配件网站模板_网站模板设置
2024-06-23 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11