青云互联怎么样

青云互联是一家提供云计算服务的公司,主要产品包括云服务器、云数据库、云存储等。它的服务稳定性和性能都得到了用户的认可,但价格相对较高。
【青云互联VPS概述】
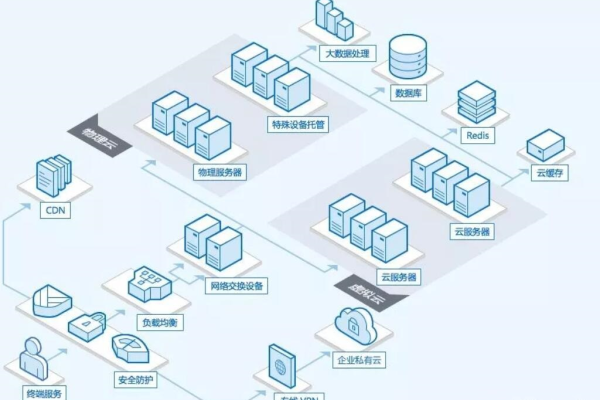
青云互联VPS(Virtual Private Server)是一种虚拟专用服务器,通过将一台物理服务器划分为多个虚拟独立服务器,为用户提供独立的计算资源、存储资源和网络资源,用户可以根据自己的需求选择不同的配置,实现灵活、可扩展的云计算服务。
【青云互联VPS特点】
1、灵活配置:用户可以根据自己的需求选择CPU、内存、硬盘等资源配置,满足不同场景的需求。
2、高性能:采用高性能硬件设备,提供稳定的计算、存储和网络性能。
3、安全可靠:提供多种安全策略,如防火墙、DDoS防护等,保障用户数据安全。
4、简单易用:提供图形化管理界面,方便用户进行服务器管理和维护。

5、丰富应用:支持多种操作系统和应用软件,满足用户多样化的需求。
【青云互联VPS应用场景】
1、Web网站托管:适用于企业官网、电商平台、个人博客等网站的托管。
2、应用程序开发:提供独立的开发环境,方便开发者进行代码编写、调试和测试。
3、数据库服务:提供数据库服务,满足用户的数据处理和存储需求。

4、游戏服务器:提供高性能的游戏服务器,满足游戏开发和运营的需求。
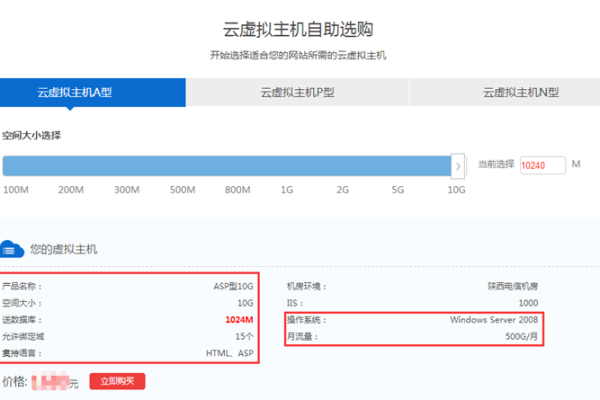
【青云互联VPS价格表】
| 配置 | CPU | 内存 | 硬盘 | 带宽 | 价格/月 |
| 基础型 | 1核 | 1GB | 20GB | 1Mbps | 99元 |
| 标准型 | 2核 | 2GB | 40GB | 2Mbps | 199元 |
| 高级型 | 4核 | 4GB | 80GB | 5Mbps | 399元 |
| 旗舰型 | 8核 | 8GB | 160GB | 10Mbps | 799元 |
【青云互联VPS购买流程】
1、注册账号:访问青云互联官网,注册一个账号。
2、选择产品:在产品列表中选择VPS产品。

3、选择配置:根据自己的需求选择合适的配置。
4、确认订单:确认购买信息,填写联系人信息。
5、付款:选择支付方式,完成付款。
6、开通服务:付款成功后,青云互联会为您开通VPS服务。
7、登录管理:使用SSH工具登录VPS,进行相关操作和管理。



热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

QQ资料卡为何显示为空?原因何在?
2024-11-11 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22