CDN目录管理,如何优化内容分发网络的存储结构?

CDN目录
CDN基础理论
CDN定义与作用
CDN的定义分发网络(Content Delivery Network, CDN)是一种构建在现有网络基础之上的智能虚拟网络,通过部署在各地的边缘服务器,利用中心平台的负载均衡、内容分发和调度功能模块,使得用户可以就近获取所需内容。
CDN的作用:CDN的主要目的是降低网络拥塞,提高用户访问响应速度和命中率,它通过缓存代理技术将源站内容逐级缓存到网络的每一个节点上,使用户不用直接访问源站,从而省去了“长途跋涉”的时间成本。
CDN工作原理
缓存和代理:CDN的工作核心是将内容缓存到离用户最近的节点上,这些节点作为代理服务器,缓存了源站的内容,用户可以直接从这些节点获取数据,从而提高数据传输速度。
请求处理流程:当用户请求某个资源时,CDN会将请求重定向到最近的边缘节点,如果该节点有缓存的数据,则直接返回给用户;如果没有,则从源服务器获取后再返回给用户。
CDN组成要素
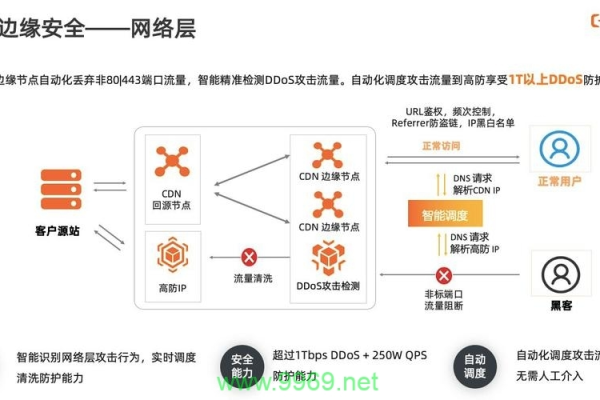
边缘节点:分布在各个地方的各个数据中心的节点,也称为“边缘节点”(edge node),它们负责缓存部分数据,响应用户的请求。
区域节点:规模更大,缓存数据更多,命中概率更高的节点,位于边缘节点之上,如果边缘节点无法命中,就到这里查找。
中心节点:最上层的节点,规模最大,缓存数据最多,如果区域节点无法命中,就回源网站访问。
CDN配置实践
配置思路与前置条件

配置思路:需要根据应用实际情况进行配置,包括文件后缀的缓存需求、实时更新的文件目录、API接口的实时查询需求等。
域名备案:在国内使用CDN服务前,需要进行工信部和公安的域名备案。
域名解析:将域名解析到CDN提供的网址,相当于CDN做第一次路由。
详细配置步骤
基础配置:包括基本信息和源站信息,源站信息指缓存不存在时的数据请求地。
访问控制:包括防盗链配置、IP黑白名单、IP访问限频、鉴权配置等。
缓存配置:涉及缓存键规则、节点缓存过期、浏览器缓存过期等。
回源配置:如合并回源、分片回源、回源HTTP请求头等。
安全与优化
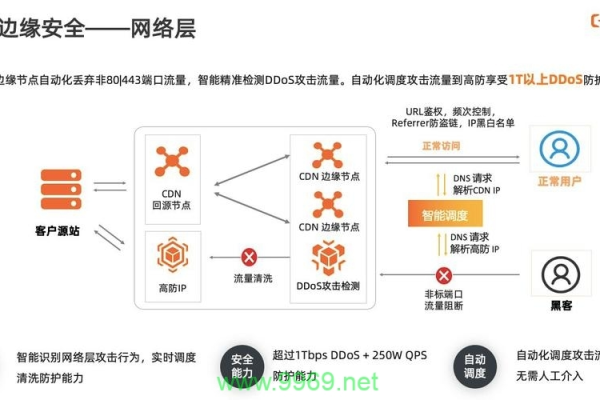
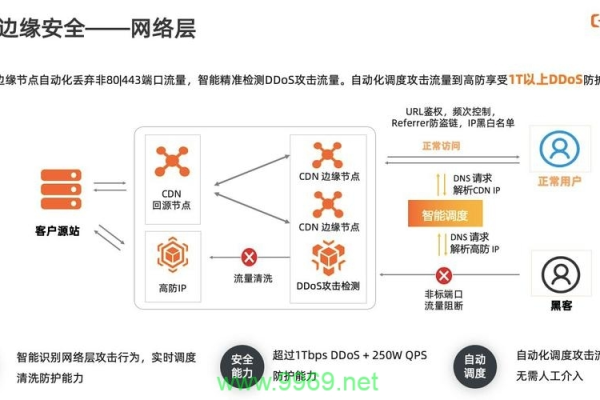
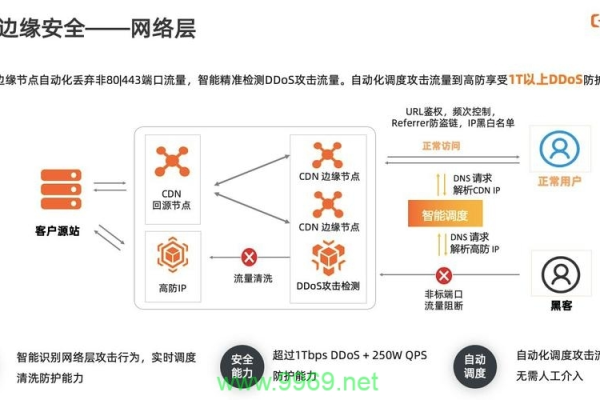
安全问题:CDN可能面临的安全问题包括DDoS攻击等,需采取相应的防护措施。

性能优化:通过调整配置减少延迟、提升传输效率,例如合理设置缓存时间、利用压缩技术等。
CDN应用场景
静态加速
网页加速:缓存并快速分发静态网页资源,如HTML、CSS、JavaScript文件。
媒体资源加速:对图片和视频等静态媒体文件进行缓存和高效传输。
动态加速
传输:通过特定技术手段加速动态内容的传输,如动态页面的负载均衡。
流媒体加速
视频直播点播:提供高效的流媒体分发,减少视频卡顿和加载时间。
音频流媒体:加速音乐流服务、网络广播等音频流的传输。

CDN效果评估
访问速度提升
减少延迟:通过就近访问原则,显著减少数据传输的延迟时间。
提高稳定性:通过全局负载均衡设备和多个节点,提升了服务的可用性和稳定性。
带宽与成本优化
变相增加带宽:通过CDN缓存静态资源,用较小的带宽支持较大的流量。
成本控制:实时关注业务需求和CDN产生的费用,避免不必要的开支。
CDN技术通过全球范围内的分布式节点网络,实现了互联网内容的高效、快速、稳定的分发与访问,从基础理论到配置实践,再到应用场景和效果评估,CDN技术已经成为现代互联网服务不可或缺的一部分,无论是提升用户体验还是优化带宽成本,正确配置和有效利用CDN都至关重要。




热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

配件网站模板_网站模板设置
2024-06-23 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

是否必须购买云数据库以配合云服务器使用?
2024-09-20 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12