上一篇
如何正确设置织梦dedecms采集中的过滤规则?
织梦dedecms采集时,常用过滤规则包括去除HTML标签、替换特定字符、截取字符串长度等。
在织梦dedecms采集过程中,使用合适的过滤规则能够有效地去除不需要的内容和广告代码,提高采集数据的质量,以下是一些常用的过滤规则及其应用示例:

常用过滤规则及应用
| 过滤正则表达式 | 说明 | |
| 标题空格过滤 | {dede:trim} {/dede:trim} | 用于过滤标题中的空格 |
| 来源作者链接保留文字 | {dede:trim}]*)>{/dede:trim} | 保留链接中的文字部分 |
| 来源作者链接去掉文字 | {dede:trim}]*)>([^{/dede:trim} | 去掉链接中的文字部分 |
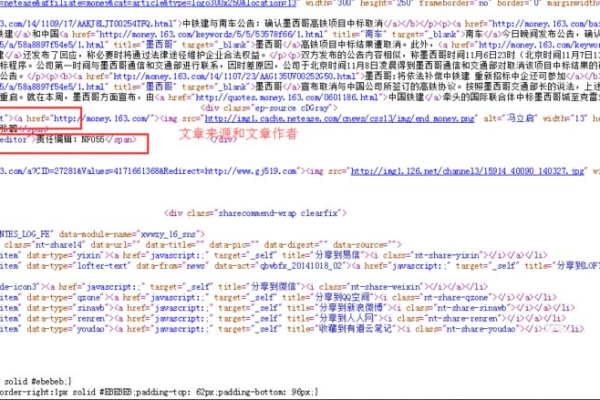
| 文章内容连接及其他广告代码过滤 | {dede:trim}]*)>([^>]*){/dede:trim} | 过滤文章中的链接和其他广告代码 |
| 过滤div标签 | {dede:trim}]*)>{/dede:trim} | 过滤掉div标签及其内容 |
| 过滤js代码 | {dede:trim}]*)>([^ | |
| 过滤未知变量字符 | 固定(.*)固定 | 替换未知变量字符为固定值 |
| 过滤GG广告代码 | {dede:trim}{/dede:trim} | 专门用于过滤GG广告代码 |
综合过滤规则
1、通用过滤规则:
{dede:trim}]*)>({/dede:trim}
{dede:trim}]*)>([^>]*){/dede:trim}
{dede:trim}{/dede:trim}
{dede:trim}<span(.*)>{/dede:trim}
{dede:trim}</span>{/dede:trim}
{dede:trim}<div(.*)>{/dede:trim}
{dede:trim}</div>{/dede:trim}
{dede:trim}<li>{/dede:trim}
{dede:trim}</li>{/dede:trim}
{dede:trim}<ul>{/dede:trim}
{dede:trim}</ul>{/dede:trim}
{dede:trim}<font(.*)>{/dede:trim}
{dede:trim}</font>{/dede:trim}
{dede:trim}<table(.*)>{/dede:trim}
{dede:trim}</table>{/dede:trim}
{dede:trim}<tbody(.*)>{/dede:trim}
{dede:trim}</tbody>{/dede:trim}
{dede:trim}<tr(.*)>{/dede:trim}
{dede:trim}</tr>{/dede:trim}
{dede:trim}<td(.*)>{/dede:trim}
{dede:trim}</td>{/dede:trim}
{dede:trim}<a(.*)>{/dede:trim}
{dede:trim}</a>{/dede:trim}
{dede:trim}<iframe(.*)</iframe>{/dede:trim}
{dede:trim}<style(.*)</style>{/dede:trim}
{dede:trim}<script(.*)</script>{/dede:trim}
{dede:trim}<option(.*)</option>{/dede:trim}
{dede:trim}<select(.*)</select>{/dede:trim}
{dede:trim}<object(.*)</object>{/dede:trim}
{dede:trim}<embed(.*)>{/dede:trim}
{dede:trim}</embed>{/dede:trim}
{dede:trim}<param(.*)</param>{/dede:trim}
2、特定过滤规则:
{dede:trim replace=''}(.*){/dede:trim}:适用于keywords字段无法添加过滤规则的情况。
相关问答FAQs
Q1:如何在dedecms中过滤标题中的空格?
A1处添加以下正则过滤即可:{dede:trim} {/dede:trim}。
Q2:如何保留链接中的文字部分?
A2:可以使用以下正则表达式来匹配并保留链接中的文字部分:{dede:trim}]*)>{/dede:trim},如果需要去掉链接中的文字部分,可以使用:{dede:trim}]*)>([^{/dede:trim}。
1、字符串过滤规则
过滤特殊字符:str_replace(array('<', '>', '"', "'", '&', '?', '/', '(', ')', '=', '+', '', '*', '^', '%', '&', '|', '~', '', '{', '}', '[', ']'), '', $str);`
过滤HTML标签:strip_tags($str);
过滤URL:$url = preg_replace('/s+/', '', $url);
2、字符长度过滤规则
限制标题长度:$title = mb_substr($title, 0, 50, 'utf8');
限制内容长度:$content = mb_substr($content, 0, 200, 'utf8');
3、关键词过滤规则
过滤关键词:$keywords = preg_replace('/[^x{4e00}x{9fa5}w]/u', '', $keywords);
关键词数量限制:$keywords = explode(',', $keywords);
关键词去重:$keywords = array_unique($keywords);
4、图片链接过滤规则
过滤非规图片格式:$imgurl = preg_replace('/.(jpg|jpeg|png|gif|bmp|ico)$/', '', $imgurl);
图片链接转换:$imgurl = 'http://www.example.com' . $imgurl;
5、内容格式化规则
自动去除空格:$content = preg_replace('/s+/', ' ', $content);
自动去除多余换行:`$content = preg_replace('/
s*
/', '<br>', $content);`
6、字符编码转换规则
转换编码:$content = mb_convert_encoding($content, 'UTF8', 'GBK');
7、内容摘要生成规则
根据关键词生成摘要:$description = implode(' ', array_slice(explode(' ', $content), 0, 20));
8、内容审核规则
审核敏感词:$content = preg_replace('/敏感词/', '***', $content);
审核违规内容:$content = preg_replace('/违规内容/', '***', $content);
以上规则仅供参考,具体实现时可能需要根据实际情况进行调整。在使用这些规则时,请确保您了解每条规则的用途和影响,并根据您的具体需求进行适当的修改和调整。
本站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本站,有问题联系侵删!
本文链接:http://www.xixizhuji.com/fuzhu/100336.html