如何利用GitHub CDN加速网站内容的加载速度?

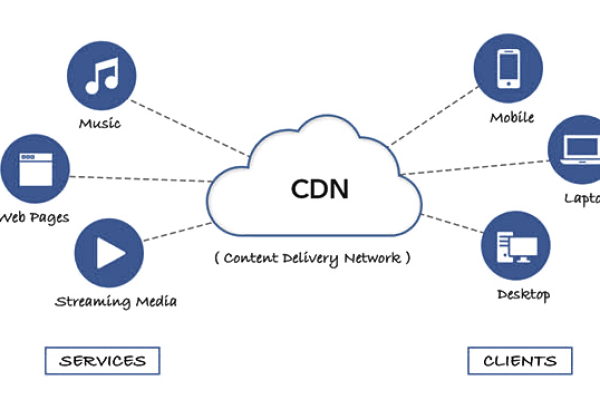
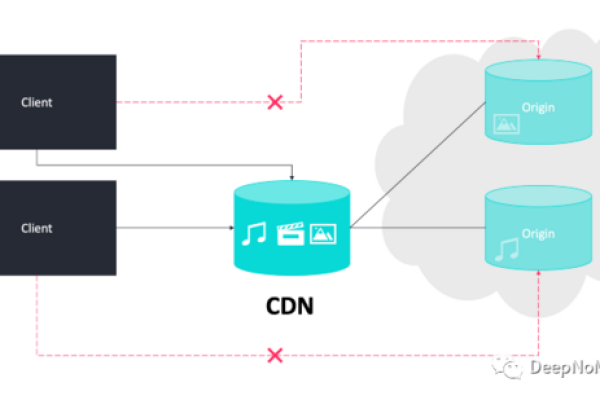
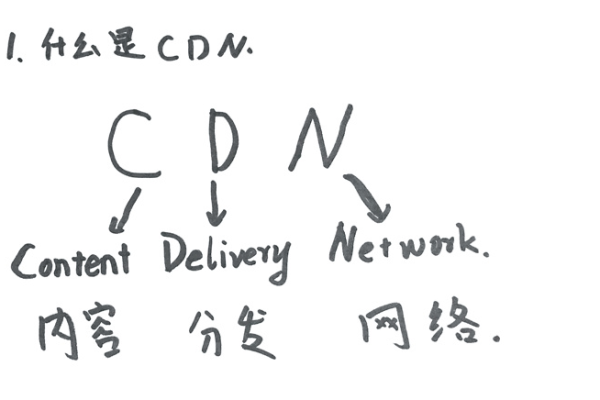
GitHub CDN(内容分发网络)是一种利用GitHub全球服务器基础设施来加速托管在GitHub上的静态文件(如图片、JavaScript、CSS等)的加载速度的服务。开发者可以通过特定的URL格式直接从GitHub的 CDN中获取这些文件,以实现更快的内容传递和更好的用户体验。
【Github CDN简介】
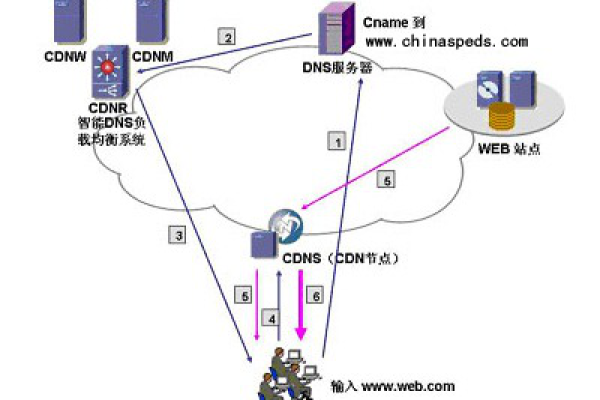
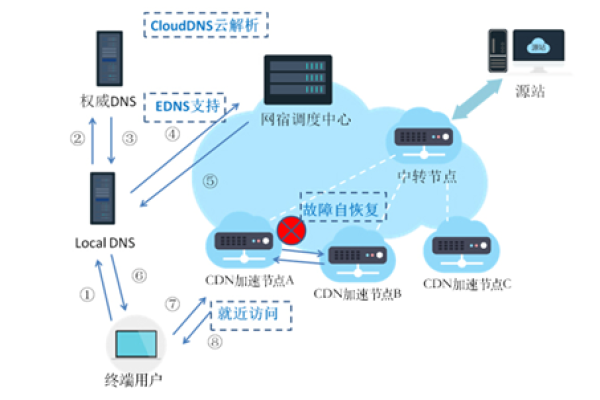
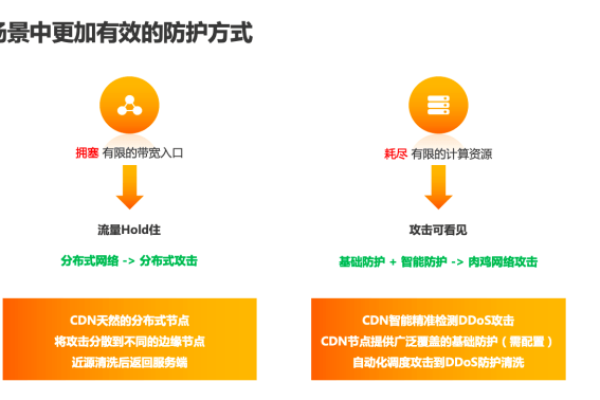
Github CDN是一个利用内容分发网络(CDN)技术提高GitHub访问速度的优化方案,通过特定的CDN服务提供商,如GitHub+Jsdelivr、DNS拦截等,用户能够在国内享受到更快的访问速度和下载体验。
【Hosts文件修改】
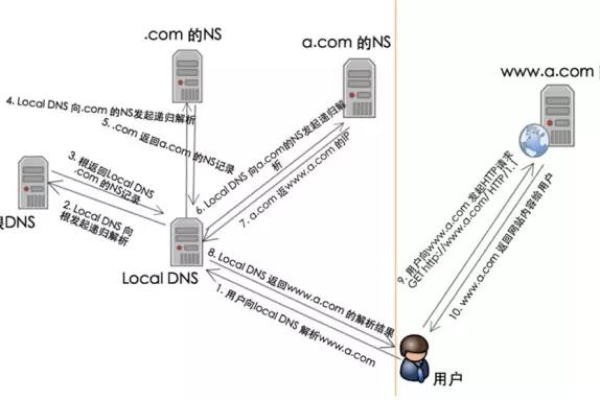
修改系统Hosts文件是一种常见的优化手段,通过绕过国内DNS解析,直接访问GitHub的CDN节点,实现访问加速,具体步骤如下:
1、查询GitHub相关链接的DNS解析地址
2、编辑Hosts文件,添加相应的解析记录

3、保存并测试配置是否生效
需要注意的是,修改Hosts文件可能需要管理员权限,且操作应谨慎以避免影响系统稳定性。
【静态资源存储与分发】
GitHub不仅可以作为代码托管平台,还可以作为静态资源的存储空间,结合CloudFlare的内容分发和缓存管理功能,用户可以搭建一个高效的个人CDN,具体步骤包括:

1、创建GitHub仓库并上传静态资源
2、配置GitHub Pages以托管静态资源
3、设置CloudFlare的解析和缓存规则
4、通过CloudFlare的CDN服务访问资源

这种方法适合于需要大量分发静态资源的个人或组织,能够有效提高资源的加载速度和可用性。
Github CDN通过多种技术和方法实现了对GitHub资源的快速访问和下载,无论是通过CDN服务提供商、修改Hosts文件还是利用GitHub和CloudFlare搭建个人CDN,用户都可以根据实际需求选择最合适的方案,这些优化手段不仅提高了访问速度,也增强了用户体验,尤其对于需要频繁访问GitHub资源的用户来说,具有重要的实用价值。

热门文章
-

云服务器在搭建实时报警平台中扮演什么角色?
2024-10-04 -

MySQL存储过程的高效使用与编写指南,如何优化C语言中的MySQL存储过程?
2025-03-08 -

为什么服务器在技术世界中如此受到青睐?
2024-10-08 -

微信中拉黑某人后,其头像显示状态会有什么变化?
2024-11-12 -
配件网站模板_网站模板设置
2024-06-23 -

如何检查网络连接状态以确保设备已连接到互联网?
2025-03-01 -

如何轻松租用云服务器,关键步骤和技巧指南
2024-09-22 -

QQ资料卡为何显示为空?原因何在?
2024-11-11